
-2.png?width=400&height=200&name=Lightning%20Opensource%20(Text%20version)-2.png)
An open source framework for modern query federation and data preparation
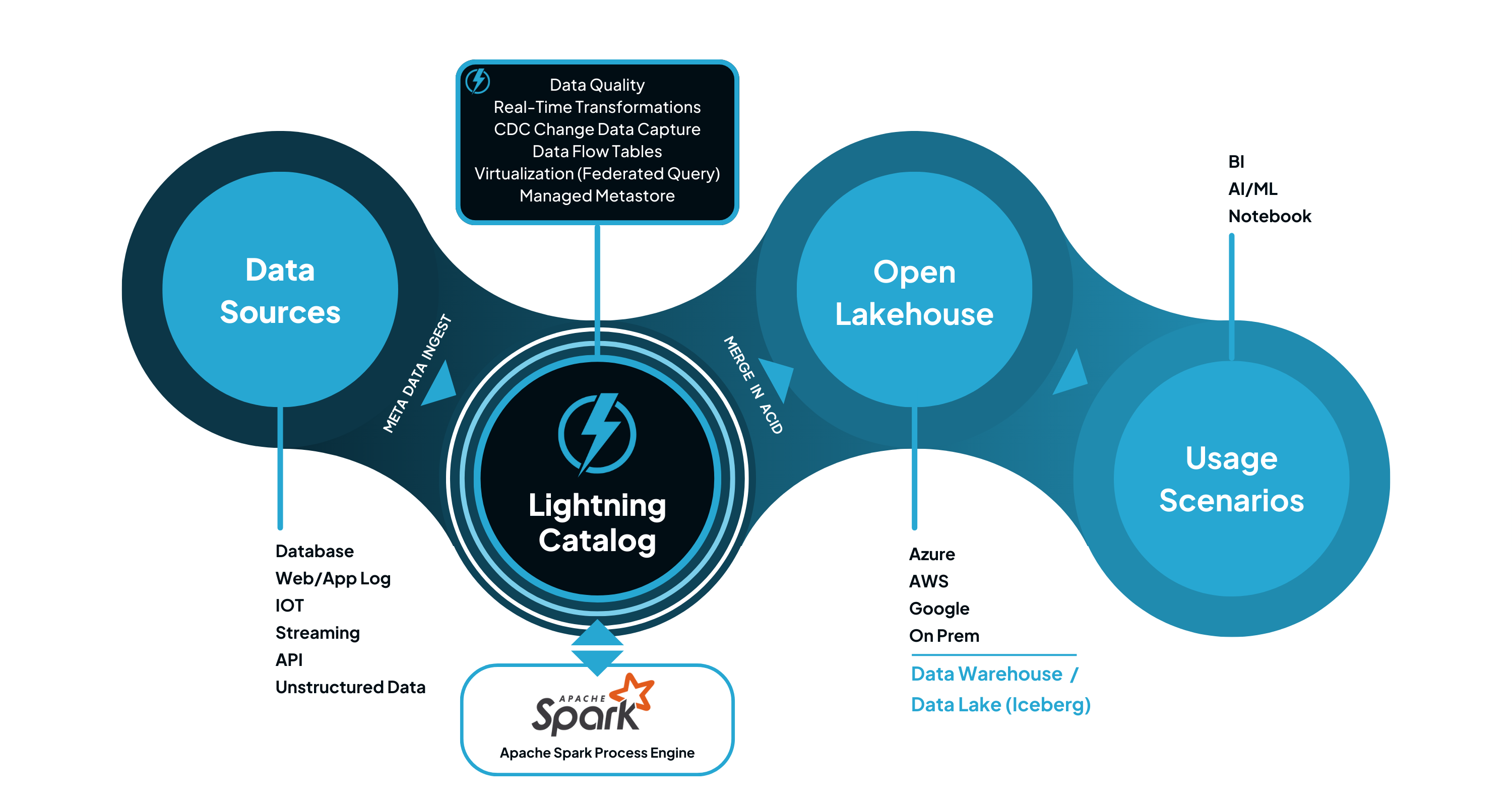
Overview
Lightning Catalog is a fast, lightweight and intuitive Spark based data catalog for the preparing data at any scale for ad-hoc analytics, data warehouse, lake house and ML projects.
Unified Access
Move data from source and legacy systems to target state while continuing the business.

Query Federation
A single view of all your data transformed into one unified semantic model and business language.

Enable Data Science Workloads
Lightning Catalog can remove the burden of data preparation workload for ML engineer, and help them focusing on building model.

Simplified Pipeline Execution Engine
Lightning Catalog simplify the life cycle of data engineering pipe line, build, test and deploy by leveraging Data Flow Table
|
Fully Managed Catalog built in file systems (HDFS, Blob, and local file) which allows version control. |
|
Support Apache Spark Plug-in architecture. |
|
Support running data pipeline at MPP scale by leveraging Apache Spark and optional NVIDIA GPU |
|
Support running ANSI SQL and Hive QL over source systems defined in the Catalog |
|
Support multiple namespace. |
|
Support data quality by integrating Amazon Deequ. |
|
Support data flow table, declarative ETL framework which defines and transforms your data. |
|
Support metadata processing for unstructured data using endpoint declarations. |













![]()

![]()
![]()


